標簽:多個 png apache 數據集 isp code 圖片 分布式 oop
Kafka最早是由LinkedIn公司开发的,作为其自身业务消息处理的基础,后LinkedIn公司将Kafka捐赠给Apache,现在已经成为Apache的一个顶级项目了,Kafka作为一个高吞吐的分布式的消息系统,目前已经被很多公司应用在实际的业务中了,并且与许多数据处理框架相结合,比如Hadoop,Spark等。Kafka 使用 Avro 作爲消息序列化框架
它是无边界數據集的抽象说法,无边界意味着无限且不断增长,因为随着时间的推移,新数据会不断地到来。最基本的数据流模型,每个节点处理完数据会将数据转发给下游节点。其余特点:数据流是有序的;数据记录是不可变;可重播。
持续的从一个无边界的數據集读取数据,然后对它们进行处理并生成结果;是一种编程范式,就像请求和响应范式;请求和响应(延迟最小);批处理(高延迟和高吞吐量);
Kafka的数据单元被称为消息,消息可以看作是數據庫内的一个记录,消息由字节组成,消息可以有一个可选的元数据(键),键也是一个字节数组,消息以一种可控的方式写入不同的分区时,会用到键;批次表示为一组消息,这些消息属于同一个分区或者主题,同一批次内的数据可以进行压缩以此来提高对应的效率。
主题=數據庫中的表,一个主题可以被拆分成任意个分区,因此在无法在整个主题内保证数据的顺序性,分区可以认为是一种数据的冗余。分区也就是一个提交日志。一个主题可以多個服务器组成。
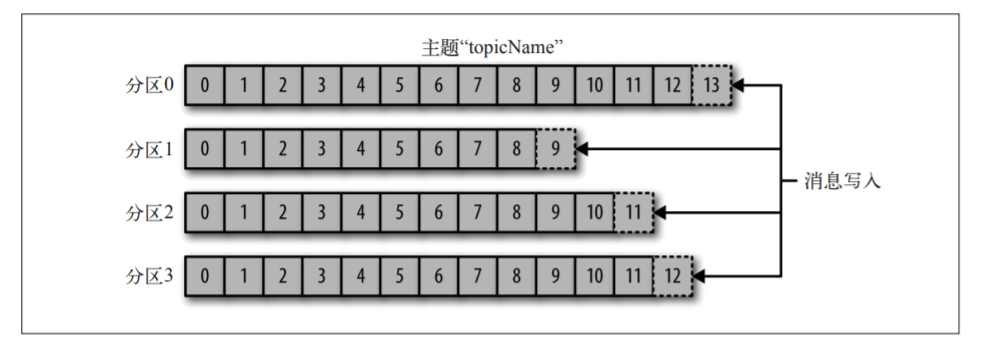
生産者創建消息,消息會被發布到一個特定的主題上,生産者在默認情況下把消息均衡地分布到主題的所有分區上。不會關心被特定寫入到哪個分區上,不過也可以指定寫入特定的分區上。通過消息鍵和分區器來進行實現,分區器會生成一個散列值,並將其映射到特定的分區上。這個可以保證同一個鍵的會被寫入到同一個分區上。
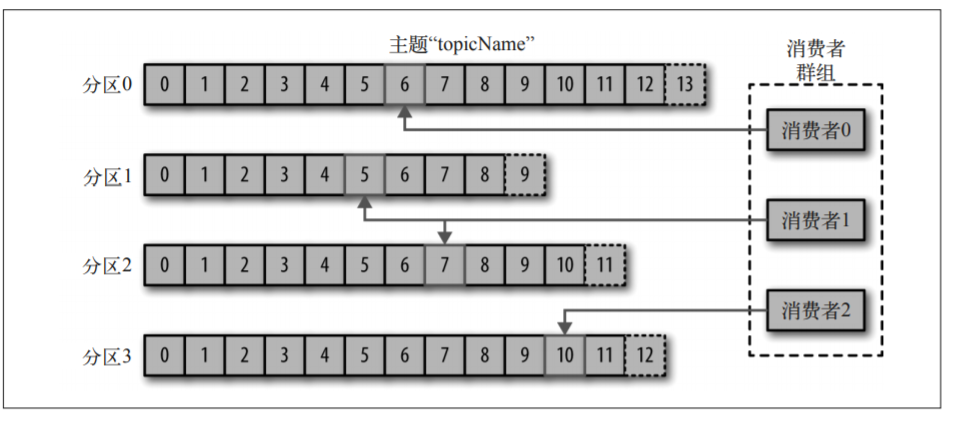
消費者讀取信息,通過訂閱主題來獲取分區內的消息,會去檢查消息的偏移量來區分已經讀取到的數據。會把讀取到的分區偏移量存儲在kafka或者zookeeper中去。消費者是消費群組的中的一部分,一個分區在同一時間只能保證被一個消費者使用。
標簽:多個 png apache 數據集 isp code 圖片 分布式 oop
原文地址:https://www.cnblogs.com/SmartCat994/p/15057815.html